
このブログ記事のシリーズでは、機械学習、とくに生成 AI と法的な問題について述べます。全 3 回を予定しており、今回はその 3 回目です。
前回は通常の機械学習や生成 AI と著作権について、これまでの基本的な考え方を確認しました。とくに、著作物であるための要件や、侵害となるかどうかの判断に用いられる類似性や依拠性といった観点、例外規定を適用するための「享受」について確認してきました。
最終回となる今回では、現在議論が進行中の事象について取り上げます。
生成 AI の利用は急激に拡大しており、これまでの基本的な考え方ではカバーできないようなケースも散見されるようになってきました。そのような事象についてどう扱うべきか、議論が進行中です。今回取り上げる内容については結論が未確定のものが多く、また、今後の議論の進行によっては結論が変わる可能性もありますが、現状の状況をまとめます。
画風をまねることが NG になるケース
一般論として、画風をまねることだけでは著作権の侵害とはならないものの、問題となる場合もあります。
前回、基本的な考え方として、画風は著作権の保護する対象でないと述べました。たとえば、技術の向上を目的として画風をまねるのは問題ありません。ほかにも、イラストレーターや漫画家の画風をまねて創作しても、それだけでは著作権の侵害にはなりません。
一方、無条件に許されるかと言うとそうではなく、いくつかの点に配慮が必要です。依拠性については明らかなので、類似性に配慮する必要があります。また、それ以外にも配慮が必要な点があるのでそれを確認しましょう。
特定のイラストレーターの画風をまねるケース
画風をまねる際に、特定のイラストレーターの画風をまねると問題になるケースがあります。作者名を明示するなどの方法で、そのイラストレーターの創作ではないと明示できるのであればまだしも、明示できていなかったがために問題になったケースがあります。
たとえば、Web サイトに表示されるバナーに使われるイラストに、特定イラストレーターの絵柄を模した画像を用いて問題になった事例があります。広告の出稿主である企業とイラストレーターが無関係であるにもかかわらず、広告を閲覧したユーザーがその企業とイラストレーターの間に何らかの関係があると誤解してしまい、イラストレーターが迷惑を被ったことがありました。
また、別の事例として、イラストレーターがポリシーとして作成しないような画像 (例: NSFW な画像) を生成 AI を用いて生成している事例もありました。この場合は、イラストレーターにとって大きなショックであると同時に、イラストレーターの社会的なイメージを損なってしまう可能性があります。
作者の持っている社会的なイメージを損なってしまうような利用法は避けるべきです。また、イラストレーターの作成した画像と、生成 AI が生成した画像を区別するための技術は、開発が進んでいるものの決定打となるものはまだありません。早まった決めつけを行うのは避けるべきでしょう。
LoRA: 特定のイラストレーターの数枚の画像から学習するケース
基本的な考え方として、訓練用のデータセットの構築や従来の機械学習モデルの訓練のために著作物を利用する場合、著作者の許諾を得なくても問題ないと前回述べました。一方、そのような考え方が疑問視されるようなユースケースも現れてきました。
最近の生成モデルは大規模であることが多く、ファインチューニングを行うことも難しかったのですが、ファインチューニングに関する技術的なブレイクスルーがあり、小規模なデータセットを使った強力なファインチューニングができるようになりました。LoRAとよばれる技術により、大規模なモデルでも比較的小規模な計算資源でファインチューニングできるようになりました。LoRA は当初、自然言語モデルに適用されましたがその後、Stable Diffusion と同時に用いられるようになりました。現在はアプリケーションに組み込まれてより使いやすくなっています。
LoRA による生成モデルのファインチューニングは小規模なデータセットで実施できる点が特徴的です。数十枚から実施できるので、さきほど述べた特定イラストレーターに類似した画像を出力できるモデルを訓練できます。
LoRA のような技術を用いて、少量のデータセットでファインチューニングする場合の著作物の利用について、享受目的ではないとは言えないのではないかという解釈が出てくるようになってきました。
これに対して、「学習データをそのまま出力させる意図までは有していないが、少量の学習データを用いて、学習データの影響を強く受けた生成物が出力されるようなファインチューニングを行うため、著作物の複製等を行う場合」に関しては、具体的事案に応じて、学習データの著作物の表現上の本質的特徴を直接感得できる生成物を出力することが目的であると評価される場合は、享受目的が併存すると考えられる。
AIと著作権に関する考え方について(素案)p.4 https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/hoseido/r05_05/pdf/93980701_01.pdf
モデルの学習のために著作物を利用できるのは、享受のためではない場合でした。享受の目的が併存する場合、著作権法の例外規定である第 30 条の 4 の適用はされません。
そのため、ある利用行為が、情報解析の用に供する場合等の非享受目的で行われる場合であっても、この非享受目的と併存して、享受目的があると評価される場合は、法第 30 条の4は適用されない。
AIと著作権に関する考え方について(素案)p.3 https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/hoseido/r05_05/pdf/93980701_01.pdf
また、前回触れたように、モデルの生成物自体が著作者の直接的な競合になるので、著作者の経済的利益を害さないという前提が崩れています。このため、このようなモデルの訓練方法について、制約が課されることは大いにありえると思われます。
小規模なデータセットを用いたファインチューニングに対する著作権上の考え方は、まさに議論が進行中です。上記で引用した文章は最終盤ではありませんが、今後も追いかけていきたいと思います。
有償の文章の模倣
生成 AI は学習のために莫大な量のデータを用います。また、出力は訓練時に用いたデータとよく似る傾向があります。そのため、生成 AI の出力を通じて、学習のためのデータがエンドユーザーに流出してしまうという問題があります。
ChatGPT のような対話を行う生成 AI は文章から学習しますが、文章はクローリングにより収集されます。Web 検索のためのクローリングについては、robots.txt という標準的な方法でユーザー側で可否の制御が可能ですが、ニュースサイトでは有償記事もクローリングの対象にしているのは普通のことだと思われます。このため、クローリングで集めた訓練データの中に有償の記事が含まれてしまっているのではないかという疑いがあります。
実際、大手新聞社からはそのような報告がされています。 New York Times は彼らの記事が流用されていると主張し、Microsoft と OpenAI を提訴しました。また、日本新聞協会も文化審議会著作権分科会法制度小委員会(第3回)に提出した資料で、次のように、新聞記事との類似性を指摘しています。
有識者提出資料(日本新聞協会)p.4 https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/hoseido/r05_03/pdf/93954701_01.pdf
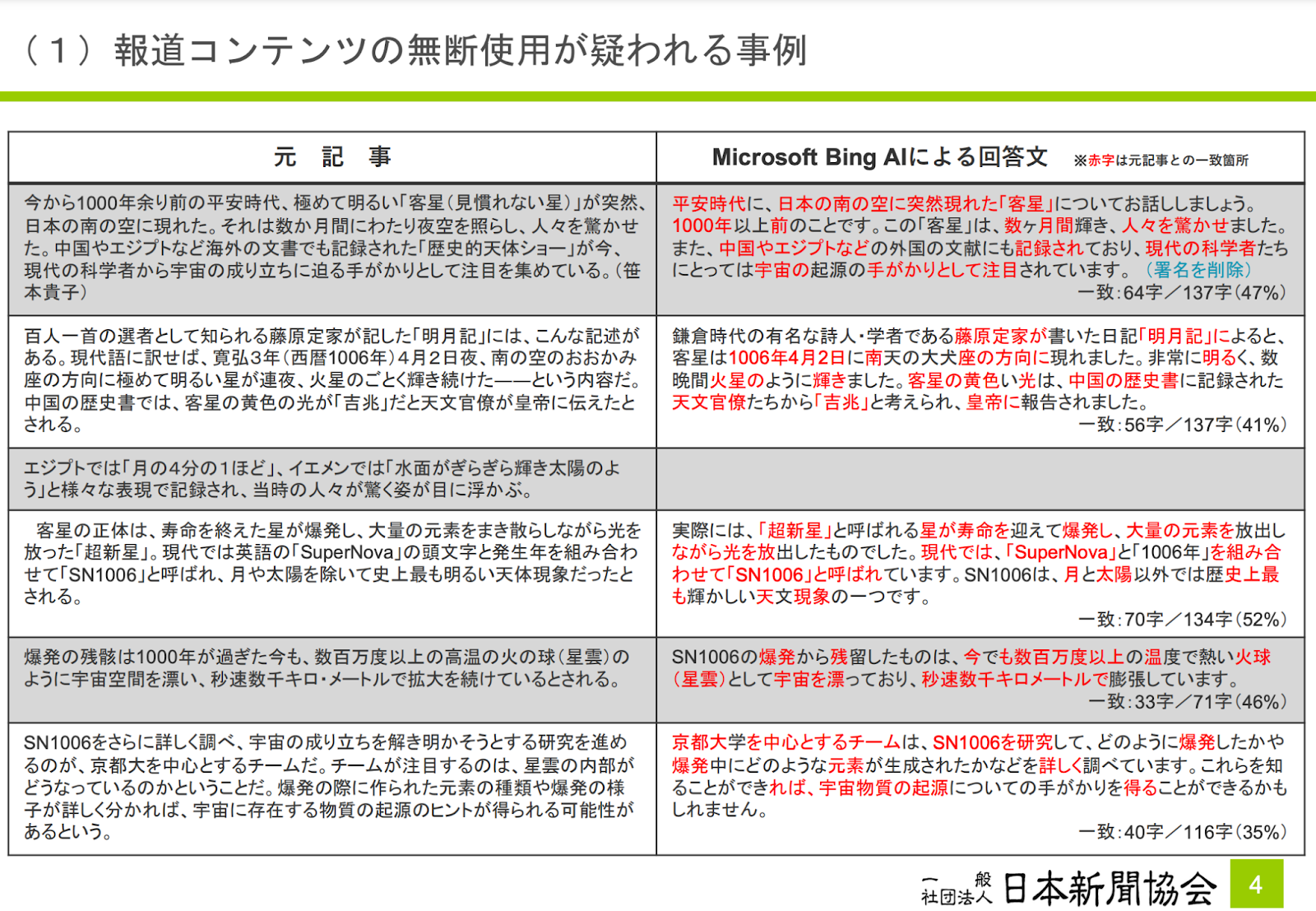
現状で、機械学習のためのクローリングに対し、ユーザー側で提供の可否を制御することは不可能です。GPTBot が行っているように robots.txt のような標準的な方法で設定を行えるようにするのが望ましいように思いますが、そのような標準は現状のところ存在しません。将来的に解決すべき技術的課題と言えるでしょう。
また、生成モデルを有償で提供しているベンダーは利益を得ているものの、データの作成者には利益が還元されていないという問題があります。これは機械学習において以前から指摘されている問題で、生成 AI の出現以降、より強く指摘されるようになりました。
生成 AI をトレーニングするためには巨額の資金が必要なため、生成 AI の作成者はプラットフォーマーのような巨大企業に限られやすく、もともと民間の報道機関は比較的弱い立場に陥りやすいという問題もあります。このような力関係を解消すべく、日本新聞協会は国に何らかの支援を期待しているようですが、どのような支援が必要なのか、議事録を確認する限り明らかになっていないようです。
さいごに
生成 AI は幅広く活用の可能性がある、有用な技術であることは間違いありません。このブログ記事のシリーズでアイキャッチとして利用している画像はすべて DALL-E を用いてブログ記事から生成しています。これらの画像が著作物として認められるかどうかはさておき、それぞれ印象的な画像だと思います。とくに今回の画像は筆者のお気に入りです。
従来の機械学習のようなテクノロジーを活用するのはデータサイエンスについてリテラシーの高い人に限られがちでした。しかし生成 AI 様子が異なっており、学生はすでにかなりの割合で利用していますし、エンタープライズな企業においても導入が進んでいます。
一方で、この記事で触れた課題も含めて、新たな課題もさまざまに発生しています。しかしながら、それらの課題に対して、技術的に見て妥当な議論がなされているように思います。著作権の議論においても、著作者を保護すると同時に、AI の提供者や研究開発にとっても、公平な状態を実現すべく議論がなされています。
また、技術的に不可能な要求はあまり出てきていません。ただし、特定のデータを訓練データセットから削除してほしいという申し出への対応が、今後必要になる可能性が高そうです。学習データのトレーサビリティは今後ますます重要になるかもしれません。
生成 AI に関する議論は国際的にもまさに進行中なので、今後も注視していきたいと思います。
注意
本ブログ記事は2023年12月末時点で入手可能な情報に基づいており、可能な範囲で正確になるよう努めていますが、正確性を保証するものではありません。また、AIと著作権について法的助言を含めた包括的な記述をめざすのではなく、テクノロジー企業の視点に基づいて限定的な側面を記述しています。
本ブログ記事内の情報を利用することで生じたいかなるトラブル、損失、損害に対しても、弊社は一切責任を負いません。個々の事例の判断は、専門家に調査を依頼する等、個人の責任において行ってください。




